
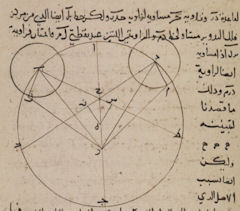
Genealogies of Knowledge Corpus
The Genealogies of Knowledge corpus is designed to enable researchers to trace the trajectory of key concepts as they enter different cultural and temporal spaces, predominantly but not exclusively through the mediation of various forms of translation.
The current focus of the project is on three historical lingua francas (Arabic, Latin and English) and on concepts relating to the body politic and to scientific, expert discourse. However, the research team is developing a set of resources and a range of methodologies that can support future studies involving different lingua francs (French being an obvious choice in the European context), different historical moments (perhaps the Enlightenment), and different constellations of concepts. To this end, both the corpora we are building and the software being developed to interrogate them and visualise the findings are being made accessible to the research community.
Translational English Corpus (TEC)
The Translational English Corpus (TEC) is a corpus of contemporary translational English. It consists of written texts translated into English from a variety of source languages, European and non-European. TEC has supported a broad range of studies in two main areas: the way in which the patterning of translated text might be different from that of non-translated text in the same language, and stylistic variation across individual translators.
» Read more
