
Overview Corpus design Corpus contents Corpus text preparation Research avenues User manual
The opposition between an ‘original text’ and a translation has often been criticised from the viewpoint that it reduces the status of the translation to that of a mere derivative product. Yet the notion of an original also conceals the fact that texts do not appear out of nothing. While for the most part not consisting of explicitly translated material, the Internet corpus constitutes a complex web of references and interactions that point towards a number of often conflicting sites of genealogical heritage. Yet how would one start to interrogate the various sources that shape a digital discursive space?
A good place to start is quotation. Quotation, a conscious and signalled reference strategy, often indicates an appeal to authority, and it may serve to identify the specific historical dialogue a certain textual intervention aims to take part in. Examining this phenomenon can provide insight into the orientation of a particular internet outlet, without having to exhaustively study its content. One may aim to study, for instance, revolutionary journals founded in the second decade of the 21st century. In the Internet corpus, Salvage Zone and ROAR Magazine would, among others, fit that description.
Research steps (more info on software)
- Select one of the relevant outlets through the subcorpus selector and generate a word frequency list. Scroll through the frequency list to identify proper names denoting people. Looking for names is the most efficient strategy for identifying quotes in an electronic corpus, as corpora do not lend themselves readily to searches based on punctuation marks and similar signals of reported speech. Once generated, the frequency list will reveal that Trump is the most frequent name in the articles from Salvage Zone, at 420 occurrences. Corbyn, Sanders and Assad, in that order, complete the list of most frequently mentioned people. For ROAR Magazine, the order is Bookchin, Öcalan, Trump and Marx.
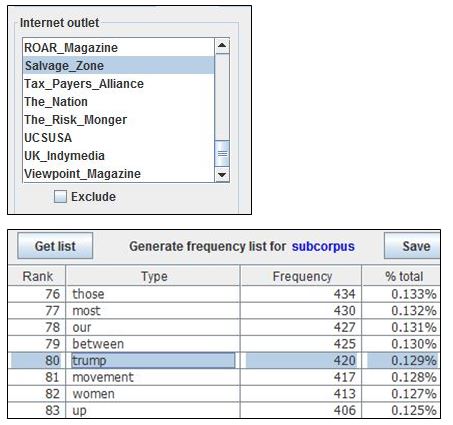
- Use the concordance browser to search for the names in question in each outlet. Examine the concordance lines returned: are they, in fact, instances of quotation, or do the names referenced fulfil another textual function?
- Identify patterns of usage in each outlet. Perhaps Sanders is quoted at length, while ‘Assad’ just serves as a placeholder to refer to a certain regime. Derive from these patterns of usage the respective positions of the people mentioned within the textual universe. Start by inferring a negative or positive evaluation, and construct a hierarchy of authority and dismissal within the outlet studied. Use this hierarchy to shed light on the quotation practices observed: who is quoted, how and why, who is paraphrased, and who is named but silenced?
- Compare your observations across publications. Why is Trump found in the company of both Sanders and Marx? Do Corbyn and Bookchin fulfil similar functions in either journal? What, in the end, do naming and referencing practices reveal about the publication’s heritage and perspective? Finally, what is hidden in quotation? Why is it, for instance, that translation does not seem to require acknowledgment, even where interlingual exchange is clearly present, as in the concordance extract below?

- Further research steps might involve searching the whole Internet corpus for the names found in the initial publications of interest, in order to identify similar or divergent patterns in other outlets. It is also possible to expand the search to other proper names, including those of political parties. It is possible, in short, to follow any patterns revealed initially to see what world is represented in publications that, due to the fragmentary nature of the Internet, can at first appear difficult to approach and investigate as a whole.
Further reading
Buts, Jan (2020) ‘Community and Authority in Roar Magazine’, in Mona Baker and Henry Jones (eds) Genealogies of Knowledge: Tracing the Mediation of Political and Scientific Concepts across Time and Space. Collection in Palgrave Communications.
