Overview Corpus design Corpus contents Corpus text preparation Research avenues Project team Past events
The Genealogies of Knowledge corpus consists of four main subcorpora that can be accessed by clicking on ‘File’ in the concordance browser once the software is launched: Greek, Arabic, Latin and English.
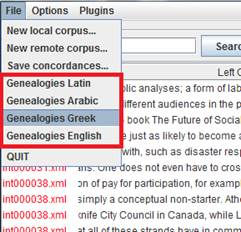
The default option is the English subcorpus. This is further subdivided into the Modern and Internet subcorpora: for guidance on selecting either or both of these English sections of the corpus, see the relevant section of the user manual.
- Content of the Greek corpus
- Content of the Arabic corpus
- Content of the Latin corpus
- Content of the Modern English corpus
- Content of the Internet corpus
The contents of these corpora are guided by the design principles derived from the project’s research agenda. However, copyright restrictions have in some cases prevented us from including works that would have been important to incorporate in all five corpora.